A while back, I was pentesting a website which would allow people to upload PDF files describing their project. Those PDFs would then be reviewed by an employee, approved and put online on the company’s website. Since I already knew that PDF is more of an execution environment (with JavaScript, ActionScript and FormCalc, there’s at least three Turing-complete languages inside Adobe Reader) than a document format, I was thinking this might not be the best idea ever.
Unfortunately, I did not find the time back then to make a proof-of-concept of a PDF that would display different content depending on some external condition, such as where the PDF was located or what time it was. For some reason the idea that I did want to make a PoC came back to me recently though and I spent a few hours this weekend to make it happen.
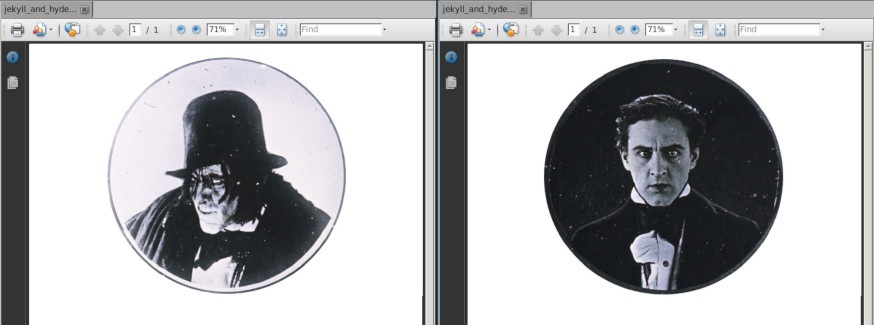
The above screenshot shows a PDF which when opened in Adobe Reader randomly either shows Dr. Jekyll or Mr. Hyde. So how does this work? The file was generated using the jhpdf.py script I made. It uses the Adobe XML Forms Architecture to embed two images and mark one as hidden. When opening the file, JavaScript code is executed which either resets the hidden flag of the second image or does not (in the above case based on a simple Math.random() <= 0.5 condition.
In case you want to build one yourself, you can think about possible conditions by looking at the JavaScript for Acrobat API Reference document. It offers lots of interesting properties such as the file path of the document, the current time, up to screen resolution and installed printers.
Note that if the document is opened in a reader which does not support XFA, it will just show a blank document.